![]() 政策與經濟
政策與經濟
![]() 政策與經濟
政策與經濟
4月18日,在奇點智能技術大會「AI+行業落地實踐」分會場,中能拾貝創始人兼CTO劉勇給出了他的判斷與答案:中國作為制造業大國,人工智能最大的賽道未來將會在工業。但工業場景對確定性、可靠性和安全性的極致追求,決定了它不能簡單復制消費互聯網的AI落地路徑,必須建立一套專屬的工程化理論方法和可靠的技術工具集。

基于這一判斷,中能拾貝提出了以“SDKIP(Signal信號數字化→Data數據資產化→Knowledge知識語義化→Intelligence智能自主化→Purpose意圖具象化)”為核心的方法論,并發布了其工業智能操作系統(CyberwIIOS)及工業模型引擎(IIOS IME),破解長期困擾工業領域的“數據割裂”與“知識隔閡”難題。
工業將成為人工智能未來最大的落地賽道
“今天我的主題,在 CSDN 的會議上應該算是比較特別的一個。中國作為制造業大國,我個人認為,人工智能未來最大的賽道,一定會在工業。” 演講開篇,劉勇便直接點明了工業賽道在 AI 時代的核心價值,同時也直面行業現狀:人工智能在工業領域的應用落地,整體節奏仍相對滯后。
在他看來,這種滯后并非源于行業需求不足,而是工業場景的核心屬性決定的 —— 工業生產對確定性、可靠性、安全性有著極致的、近乎苛刻的追求,這與當前通用大模型天生的不確定性、幻覺問題形成了本質矛盾。而這,也正是整個工業智能行業必須面對的核心課題:想要讓人工智能在工業場景真正落地,我們是否應該擁有一套專屬的工程化理論方法,以及一套能夠完整支撐落地的技術工具集?
這也正是劉勇本次分享的核心主題,更是中能拾貝深耕行業 21 年給出的答案。作為國家專精特新重點小巨人企業,中能拾貝已成立 21 年,始終聚焦能源電力行業,定位工業智能產品與服務提供商,以 “拾貝” 為核心產品品牌,打造工業智能操作系統底座,構建完整的工業智能產品與服務體系,助力資產密集型企業實現數字化轉型,同時也是智能水電廠等多項國家、行業標準的發起、編制單位,是工業智能化領域的資深踐行者。
通用大模型,能解決工業 AI 的落地難題嗎?
歷經二十余年的數字化建設,劉勇所深耕的能源電力行業,早已建成了能夠支撐正常業務運行的數字化技術平臺與應用體系。從物聯網、大數據、人工智能技術的底層支撐,到電力生產經營的全鏈路業務覆蓋,再到水電廠、儲能電站的安全區、控制區、生產管理區的分級體系建設,電力企業已經完成了基礎的數據支撐與應用支撐搭建。
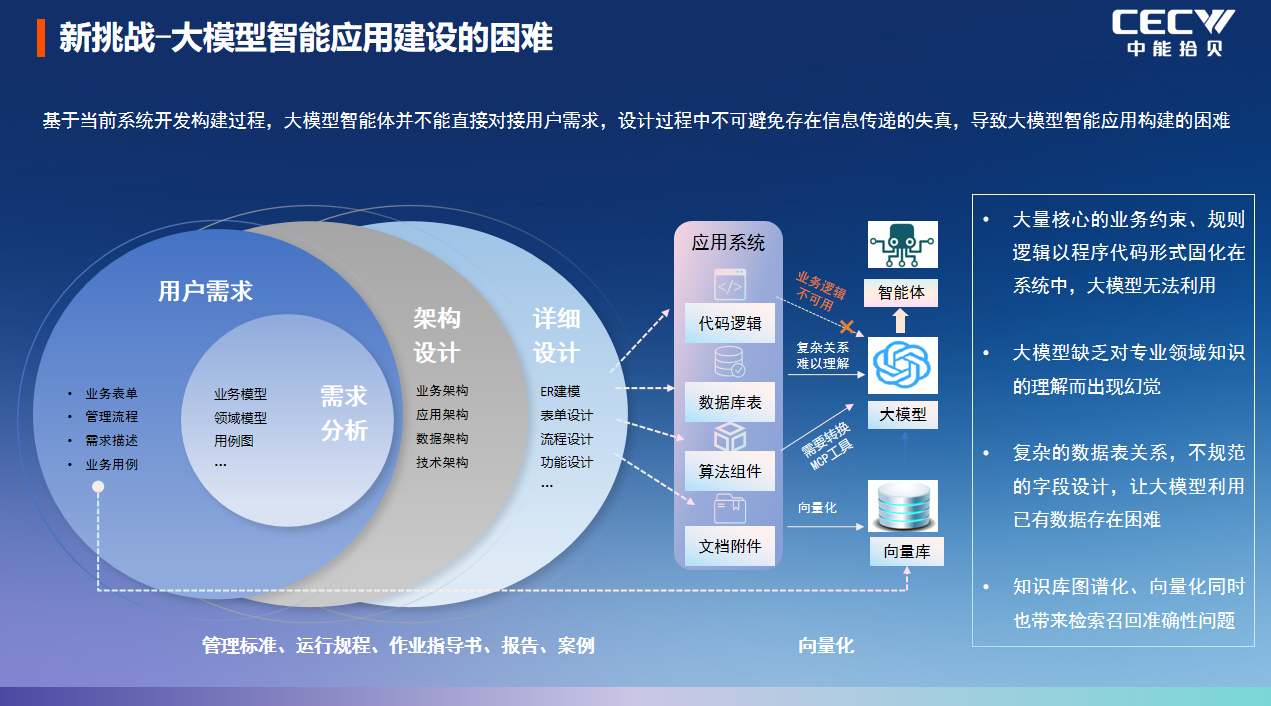
但當行業想要進一步引入大模型,構建真正可用的工業智能應用時,卻陷入了核心困境,這也引發了劉勇的核心拷問:只靠通用大模型,真的能解決工業 AI 的工程化落地難題嗎?答案顯然是否定的。他在會上拆解了工業 AI 落地的三大核心痛點,也是通用大模型無法直接突破的行業壁壘。
第一是數據與知識的雙重割裂。工業領域二十余年的數字化建設中,絕大多數核心數據與業務知識,都沉淀在了系統架構設計、詳細設計、應用代碼、復雜數據庫表關聯關系、用戶手冊與作業流程中,形成了大量數據孤島與知識壁壘。如果直接將這些原始數據與文檔輸入大模型,不僅要重復漫長的業務邏輯重構過程,重走一遍數字化的 “長征路”,更無法從根源上解決大模型的幻覺問題,難以適配工業場景的準確性要求。
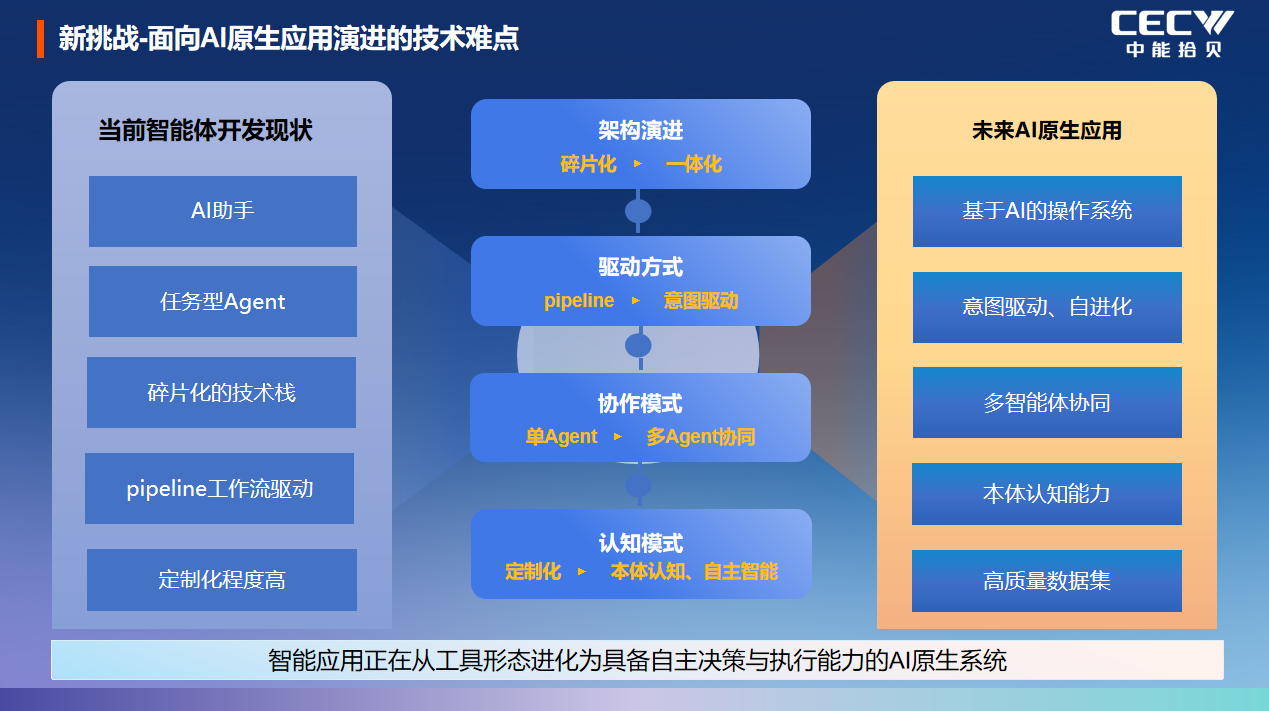
第二是智能體開發的碎片化困境。當前工業領域的智能體開發,大多停留在任務型 AI 助手階段,技術體系碎片化,依賴工作流驅動的定制化開發,無法實現 AI 原生的、意圖驅動的自動化應用構建,更難以形成具備本體認知能力的多智能體協同體系,無法適配工業場景復雜、聯動的業務需求。
第三是高容錯與零容錯的場景鴻溝。正如中國信通院余院長所言,當前大模型的應用,更多集中在高容錯的輔助工作場景。但在工業領域,尤其是能源電力行業,對設備運行、生產操作、系統控制有著絕對的安全、可靠、正確要求,任何執行偏差都可能引發設備損壞、大面積停電甚至人身安全事故,這種零容錯的場景要求,正是通用大模型難以深入工業核心生產環節的關鍵原因。
劉勇直言,工業 AI 落地的核心瓶頸,從來都不僅僅是人工智能技術的先進性不足,而是要打破數據割裂與知識隔閡,讓人工智能真正理解工業領域的策略與規則,能夠正確、可靠、安全地執行任務。
工業 AI 工程化,必須吃透的雙輪驅動核心體系
針對工業 AI 落地的核心痛點,劉勇在會上正式發布了中能拾貝打磨多年的SDKIP 工業 AI 工程化全鏈路方法論,以及支撐這套方法論落地的工業智能操作系統底座CyberwIIOS ,而這套體系的核心,正是數據與知識雙輪驅動。
SDKIP方法論的底層邏輯,是以讓工業資產更安全、更經濟、更智能的核心意圖(P)為牽引,構建從信號(S)到數據(D)、到知識(K)、到智能體(I)、再到意圖(P)實現的全鏈路閉環。這套體系徹底重構了工業 AI 的落地邏輯:將工業 AI 實施的核心工作,從傳統的應用開發與軟件設計,轉移到了數據資產構建(D)與工業知識沉淀(K)兩大核心環節上。
而支撐這套雙輪驅動體系落地的,正是兩大核心模型引擎,也是工業 AI 工程化必須吃透的核心能力:
● 信息模型:讓 AI 真正 “讀懂” 工業數據,破解數據割裂難題
針對工業數據割裂、大模型無法準確調用數據的問題,中能拾貝采用基于 MOF 的建模框架,通過M0 對象 —M1 模型 —M2 元模型 —M3 元元模型的四層建模體系,構建標準化的工業信息模型。
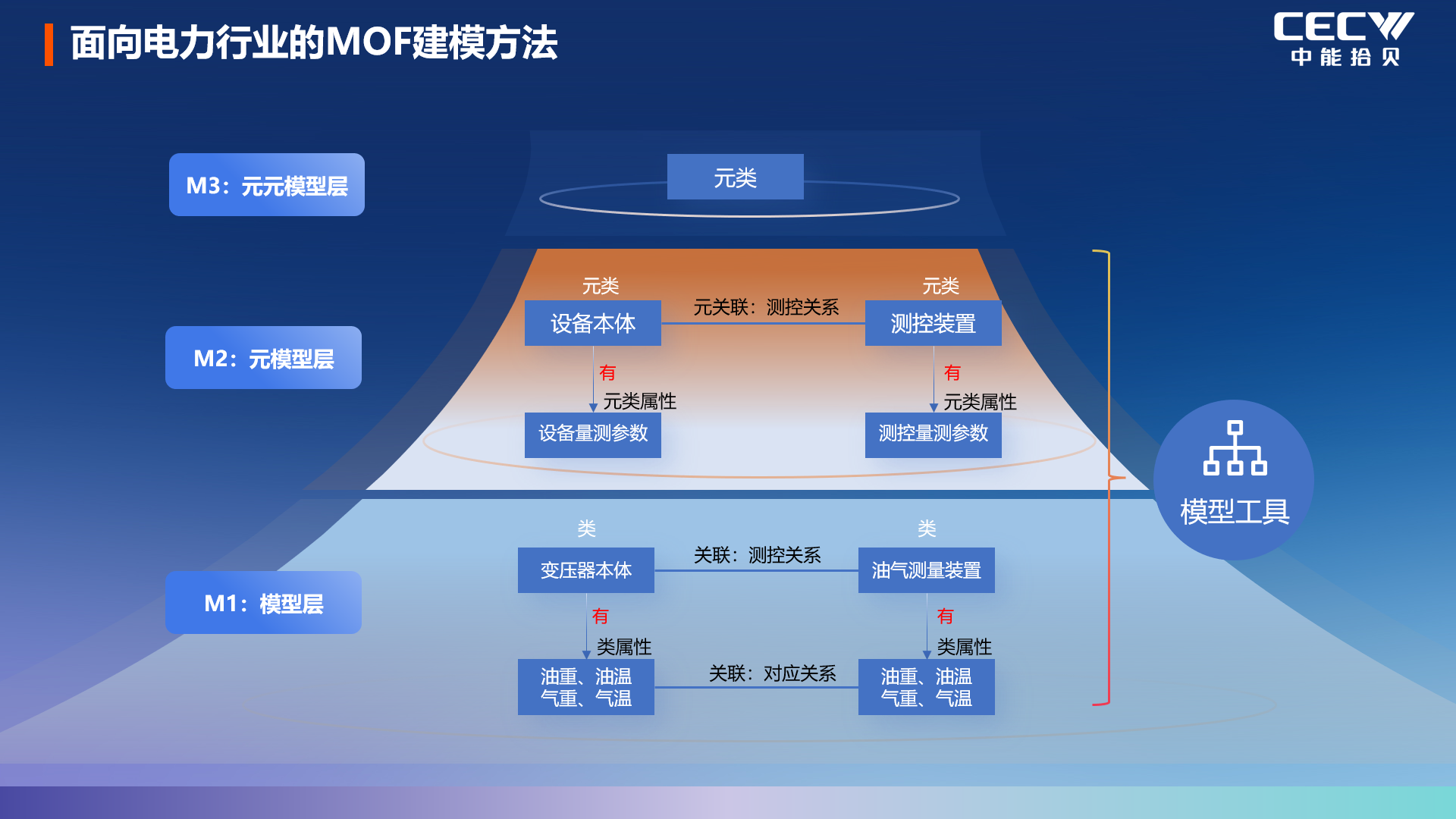
該模型通過強邏輯關聯,將數據庫中存儲的結構化數據,以及非結構化、半結構化工業數據進行統一綁定與映射,同時實現與物聯網物模型的無縫對接,讓工業現場的信號采集能夠準確映射到信息模型中,形成高度可靠的工業數據集。這一設計讓大模型在讀取、調用工業數據時,能夠實現精準匹配,從數據層面杜絕幻覺導致的錯誤輸出,讓 AI 真正 “讀得懂” 工業數據。
● 本體模型:讓 AI 真正 “理解” 工業業務,破解知識壁壘難題
解決了數據問題后,更核心的是讓 AI 理解工業場景的業務邏輯、規則與策略。劉勇團隊選擇通過本體模型,構建基于統一語義的工業專業知識體系,實現領域知識的標準化沉淀與復用。
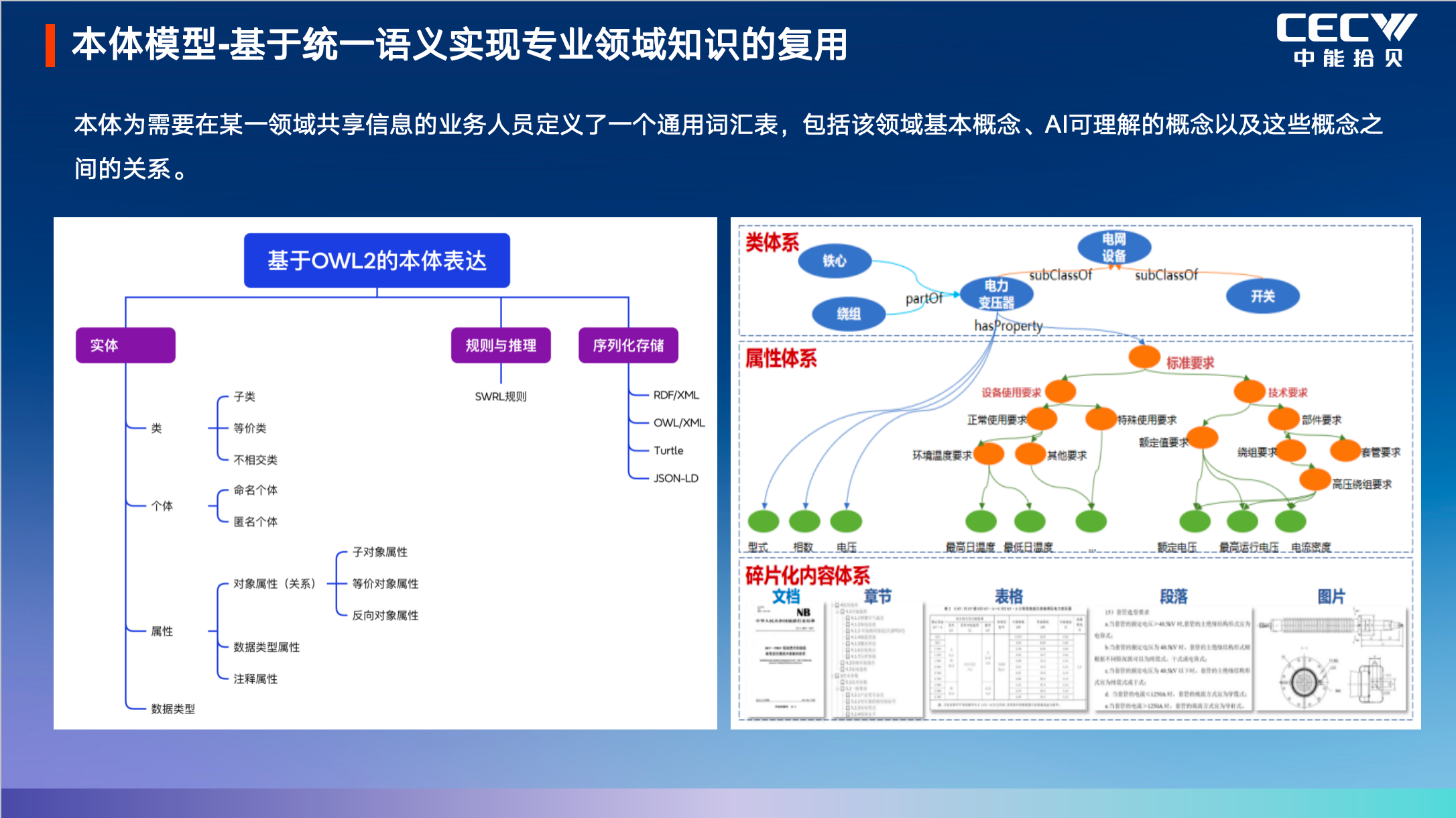
以電力基建場景為例,本體模型會將變電站建設的全工序流程、各環節的施工與驗收規范、監理的工作權責與執行標準、不同工序對應的規范條文,全部轉化為標準化的本體知識,實現工業業務全流程的強邏輯、高精準表達。通過本體模型,工業領域復雜的策略、規則、處理流程被轉化為大模型可理解、可執行的邏輯,從業務層面保障 AI 輸出的合規性與正確性,讓 AI 真正 “理解” 工業業務。
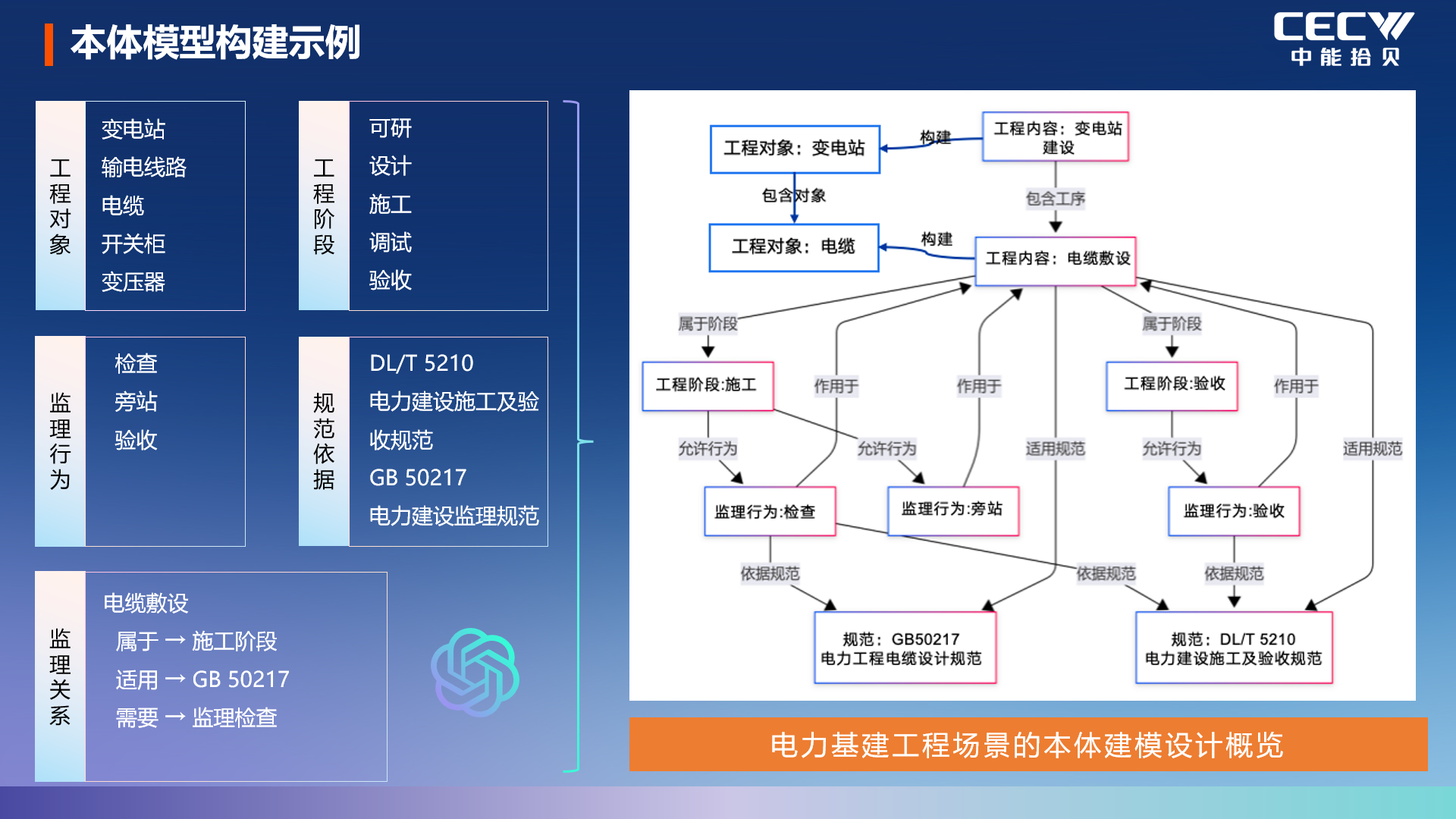
兩大模型的融合對接,構成了IIOS 工業智能操作系統最核心的IIOS IME 工業模型引擎的基礎機制。該引擎不僅實現了工業數據的強約束管理與工業知識的精準化表達,還配套了覆蓋全主流工業協議的協議棧,支撐工業現場信號的接入與處理,同時為上層應用提供統一語義定義、知識推理、數據交互、知識挖掘的核心能力支撐,成為工業 AI 原生應用開發的核心底座。

以工程化體系,筑牢 AI 落地的安全與價值底線
在劉勇看來,這套數據與知識雙驅動的工程化體系,并非消除了工業系統開發的復雜性,而是實現了復雜性的合理轉移 —— 從傳統的代碼編寫、規則理解,轉移到了本體設計、規則編寫與模型推理計算上。而這種轉移的核心價值,是讓工業智能化應用的研發,從純手工的 “古法編程”,升級為可預期、可實現的流水線式自動化生成模式。

演講最后,劉勇結合中能拾貝的落地實踐,給所有工業智能化從業者,給出了明確的落地路徑與行動建議。
在落地節奏上,要遵循分級落地、安全優先的原則。他提出了成熟的大小模型協同落地方案:在工業場站邊緣側,通過機理模型、機器學習等可控可靠的小模型處理工業信號,保障現場數據處理的確定性;在云端管理側,通過大模型實現意圖理解,打造面向工業人員的 AI 員工,支撐智慧運營、智慧生產與智慧管理。針對工業控制場景,越靠近底層的過程控制環節越審慎應用 AI,當前人工智能核心落地場景集中在多能互補、系統協控、網源協同等上層調度環節,從根源上保障生產安全。
在確定性保障上,要筑牢三道核心防線:一是以行業規程規范為核心的標準校驗,所有 AI 輸出必須符合工業行業的強制標準與規程;二是分區分級的權限管控與人工預演,基于電力行業安全分區的嚴格安全防護體系,實現 AI 應用的分級落地與人工核驗;三是以數字孿生仿真技術為核心的技術驗證,所有 AI 方案先在與真實工業系統機理一致的數字孿生體中完成仿真驗證,再落地到真實生產系統中。
在企業轉型路徑上,要走 “漸進滲透 + 全面升級” 的雙線路線:一是基于企業原有業務脈絡進行 AI 能力滲透,在設備故障診斷、資產全生命周期管理、系統控制等現有業務環節實現效率提升,這是最易落地、最快實現價值的路徑;二是圍繞 “自主執行的好員工、業務增效的好助手、輔助決策的好參謀” 三大方向,全面構建企業數字大腦與超級智能體,實現企業數字化架構的全面升級。
在商業化與行業共創上,劉勇也公布了開放的合作模式:一是標準化的工業智能工具集與產品體系的開放售賣;二是 SDKIP方法論的行業分享與共創,推動工業 AI 工程化體系的持續演進;三是各類細分行業的解決方案聯合落地,在電力等核心優勢行業開放成熟解決方案,同時與合作伙伴共創非電力行業的定制化落地方案。
責任編輯: 江曉蓓
 京公網安備 11010802020613號
京公網安備 11010802020613號